Android插件化系列二: 资源与打包流程
好的朋友们,新的一周开始了,让我们继续来学习插件化的知识吧。先回顾一下系列文章架构
根据我的行文思路,本篇文章讲解资源和App打包的一些知识。算是插件化系列的第二篇基础文章。阅读完本文后,你应该会了解:
- 资源id的组成,
- R.java的秘密
- App打包流程
资源这一部分将会先从大家的直观印象切入,逐步的加大深度。然后我会结合前半部分资源的铺垫讲解App的打包流程。大家如果阅读完以后发现,咦,这一点我还真不知道,那本文也算是有点意义了。因为本篇依然属于插件化的基础知识文章,所以还是不会讲到插件化,但是后面讲到插件化的时候会引用到本篇文章的部分知识。从另外个角度来说,本篇文章也是一篇知识比较自成一体的文章。OK,那咱们开始吧。
资源与R.java
先做一点准备工作,我们建一个工程,这个工程下面有三个module,App和我们自建的modulea,moduleb。这三个module的依赖关系是app->modulea->moduleb。然后我们在每个module里面放一点资源,比如string之类的,这里我在modulea中放了一个String叫testA, 在moduleb中放了一个String叫testB。然后我们会发现在每个module的build/generated/source/r(这个文件夹跟gradle版本有关系,3.5以后文件夹有变更)下面出现了R.java文件,这个就是android打包过程中借助于aapt工具生成的资源id目录。
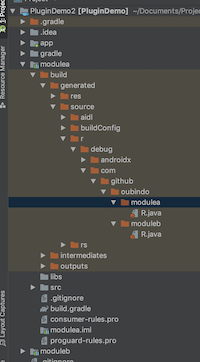
然后我们分别打开主模块和modulea的R.java。下面是主模块和普通模块的R.java文件中的id示例。1
2
3
4
5
6
7// 主模块app中的R.java
public static final int testA = 0x7f0b002a;
public static final int testB=0x7f0b002b;
// modulea中的R.java
public static int testA = 0x7f15002b;
public static int testB = 0x7f15002c;
大家可以看到:
- 为什么资源组成都以0x7f开头?
- 为什么主模块(application module)资源有final修饰,非主模块(library module,后面也称库模块)都不是final的
- 为什么同一个资源,不同模块产生的R.java中的资源id值是不统一的
为什么会这样呢?我们将在后面讲解这些内容并在最后给出结论
1.资源Id的组成
我们先看看资源Id的组成。大家都知道,资源id是一个资源的唯一标识。那么问题来了,这么多的module,这么多的资源种类,甚至还有Android自带的资源,资源id为什么不会重复呢?秘诀就在资源id的组成上面。
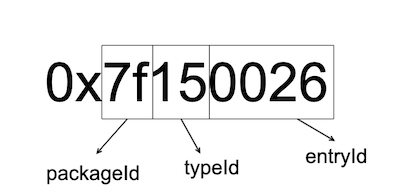
packageId: 前两位是packageId,相当于一个命名空间,主要用来区分不同的包空间(不是不同的module)。目前来看,在编译app的时候,至少会遇到两个包空间:android系统资源包和咱们自己的App资源包。大家可以观察R.java文件,可以看到部分是以0x01开头的,部分是以0x7f开头的。以0x01开头的就是系统已经内置的资源id,以0x7f开头的是咱们自己添加的app资源id。
typeId:typeId是指资源的类型id,我们知道android资源有animator、anim、color、drawable、layout,string等等,typeId就是拿来区分不同的资源类型。
entryId:entryId是指每一个资源在其所属的资源类型中所出现的次序。注意,不同类型的资源的Entry ID有可能是相同的,但是由于它们的类型不同,我们仍然可以通过其资源ID来区别开来。
通过资源id的三个区块的划分,在编译期间,同一个资源在普通的apk中只会属于一个package,一个type,只拥有一个次序,所以一个资源的id是不会和别的资源重复的。当然这只是正常情况下,要是我们有部分资源没有参与打包呢?比如说我们要说的插件化,插件化是要下发一个插件,插件中当然也有资源,这部分资源是没有经过统一的编译的,那么就可能存在和宿主(插件要下发到的App)资源冲突的情况。比如你已经给梁山排好了108将,每个人都有一个称号,但是从山下又来了一个“及时雨”宋江,那岂不是同时存在两个及时雨了,听谁的呢?梁山就会大乱,app也是如此。
为了避免这种情况,插件的资源id通常会采用0x02 - 0x7e之间的数值,避免和宿主资源冲突。至于怎么做到的,等后面的文章再聊~
2.资源id的使用
我们通常会在编码的时候使用类似于R.layout.xxxx一类的引用,这些引用就是R.java文件中的字段。并且我们在主模块和library模块中使用这些id的时候,好像并没有什么区别,那么这两者中的id真的是毫无区别吗?
我们先看看在主模块中和库模块中分别去使用id的区别。我们分别在app模块和modulea模块中分别建一个Activity。每个Activity中有一段这样的代码,大家应该都比较熟悉1
2
3
4override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
然后我们点击Android Studio的Tools->kotlin->show kotlin bytecode直接看这个类的字节码。当然直接看字节码还是比较难,我们再点面板上的decompile,把它解析成java代码。然后我们就会发现,有点细微的区别。
1 | // 主模块的代码 |
大家可以看到,主模块中的R.layout.xxx完全是作为常量,直接内联进了代码中。而库模块中的R.layout.xxx, 依然是作为变量引用到了代码中。这个规律在编译期间也是存在的。这个规律和前面对R.java中的字段的处理是一致的,也即是说,
- 主模块中的R.java中的字段以final修饰,以常量形式存在。
- 库模块中的R.java中的字段不以final修饰,以变量形式被项目中的代码所引用。
3.资源的合并
通常apk中的资源来源主要是3个,具体可以参考官网:
- 主资源(main source set):比如src/main/res
- 编译变量(Build variant source set): 比如src/demoDebug/res
- 库文件依赖(libraries): 也就是我们引进的aar。
一个资源通常会使用它的文件名作为标识,也就是说,相同resource type(anim/drawable/string等)和相同resource qualifier(比如hdpi, value中的语言等)下相同文件名的资源,系统会认为他是唯一的。那么单一module下可能就会有相同的资源存在,比如有多个主资源集。那么当出现这种冲突的情况的时候,系统会怎么处理呢?系统会进行合并,低优先级的资源会被覆盖掉。
覆盖的优先级如下:
build variant > build type > product flavor > main source set > library dependences
举个栗子,如果我们主资源集下有两个资源: res/layout/a.xml, res/layout/b.xml, build type文件夹下面有res/layout/a.xml。那么最后打包生成的apk中的res/layout/a.xml来自于build type, res/layout/b.xml来自于main source set。
除了单一module不同文件夹下的资源覆盖,不同module间也会有资源覆盖。比如app模块依赖了modulea,两个module中都有一个资源文件res/layout/a.xml,那么最后编译的apk中的res/layout/a.xml一定是app模块下定义的那个。
资源合并有什么实际意义呢?我个人认为通过资源合并可以实现更高级别的自适应打包。比如说,我们可以为不同的product flavor去设置不同的资源,比如页面xml,这样,只要改一下product flavor就能打出不一样的包,实现更高级别的自适应。
4.R文件的生成
上面讲了资源id的一些机制,接下来我们来探讨一下R文件的生成机制。这里的规律是基于gradle 3.1.2。
首先我们先看一下数量上的规律,还是以我们上面的例子为例。三个module的依赖关系是app->modulea->moduleb。modulea中有个string叫testA,moduleb中有个string叫testB。最后我们发现app模块下面有三个R文件。
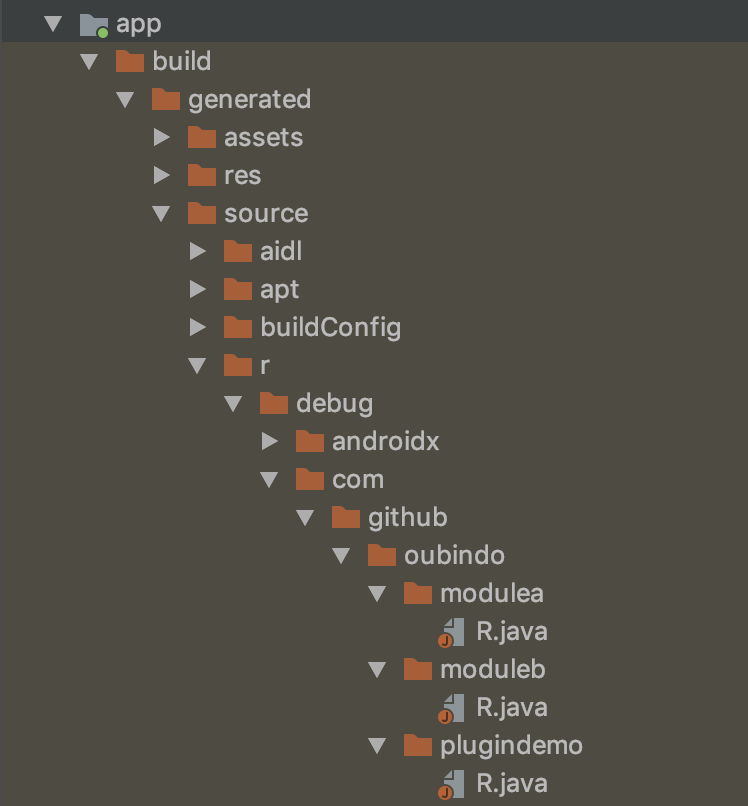
并且发现plugindemo(也即是App模块)下面的R文件里包含了我们在modulea和moduleb中定义的string。
通过上面的例子可以给出结论,用一个图可以说明。
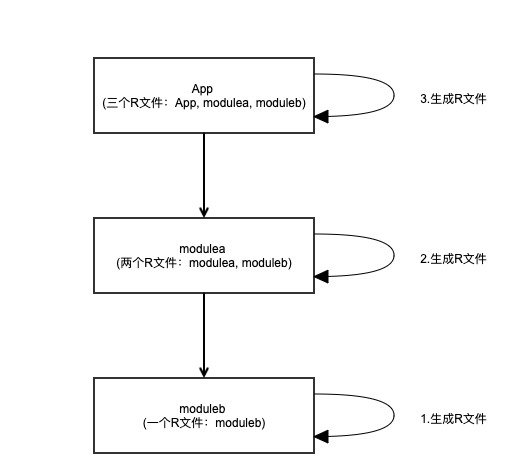
1.数量的规律:一个module被编译的时候,会生成当前module的R文件,并且该module依赖的module或者aar也会在当前module生成R文件。这种依赖关系不同于gradle里面的implementation依赖传递,implementation是跨级不能传递,但是R文件的生成是跨级可以传递的。所以,
module的R文件数 = 依赖的module/aar数量 + 1(自身的R文件)
举个例子,A模块依赖了B模块,同时也依赖了fresco,那么他生成的R文件有几个呢?答案是三个,B模块,fresco,和自身的R文件。
2.生成顺序的规律,三个模块的依赖关系是app->modulea->moduleb。生成R文件的顺序是从底层到上层,逐层生成。也就是说先生成moduleb的,再生成modulea的,再生成app模块的。
3.资源的规律:上层模块会把所依赖的模块的R文件merge进去。比如app模块并没有testA和testB这两个string,但是app的R文件却包含了这两个资源的id。这就是因为上层的模块把下层模块的资源给merge进去了。
5.总结
讲完了这些规律,我们就可以回答小节一开头提出的三个问题了。
1.为什么资源id都以0x7f开头?
因为这些资源都是应用包的资源,统一是0x7f开头
2.为什么主模块(application module)资源有final修饰,非主模块(library module)都不是final的?
比较早的aapt的版本生成的非主模块的资源id确实都是final修饰的,这样会带来一个问题,这些资源id全部内联到代码中,一旦新增或者删除,修改了资源,资源id就会有变化,所有的代码都需要重新编译,造成严重的编译耗时。后来改为主模块final常量方式内联,非主模块引用方式,这样等按照从下到上编译到App模块的时候,所有的资源id都已经确定了,底层模块的资源只需要通过引用就能拿到自己对应的id,而修改(新增,删除,修改)了资源之后,也只需要重新生成R文件就好了。编译耗时大大减少。
3.为什么同一个资源,不同模块产生的R.java中的资源id值是不统一的?
因为资源id只是表示资源的次序,而不是别的跟资源本身绑定的属性。当到了不同的模块以后,参与编译的资源变多了,那次序肯定会改变。资源id也就改变了。并且子模块的资源id只是引用形式存在于代码中,id具体是什么值并不是很care。
不知道大家看完这些,有没有什么收获呢?
6.补充知识
不知道大家有没有用过ButterKnife这个依赖注入框架,这个框架最核心的使用场景就是使用注解进行依赖注入。比如1
(R.id.user) EditText username;
大家应该常见这种用法,那么,这里有没有什么玄机呢?我们上面讲到了,非主模块中资源id是变量,没有final修饰。但是注解大家都知道,传入的参数必须是final常量。这样的话岂不是相悖了吗?
其实上面的两个结论都没有错。Butterknife针对这种情况做了一个骚处理。他直接copy了一份module中的R.java,搞了个R2.java,把R.java中所有的资源id全部改为final的,这样就能在注解中使用了。等到真正使用的时候,再进行替换,使用真正的主模块的生成的资源id。
具体可以参考R.java、R2.java 是时候懂了
App打包
打包流程这一块我会先讲述基本流程,然后会补充一些关于打包流程的应用的扩展知识。
1.打包流程
先来一张打包流程图。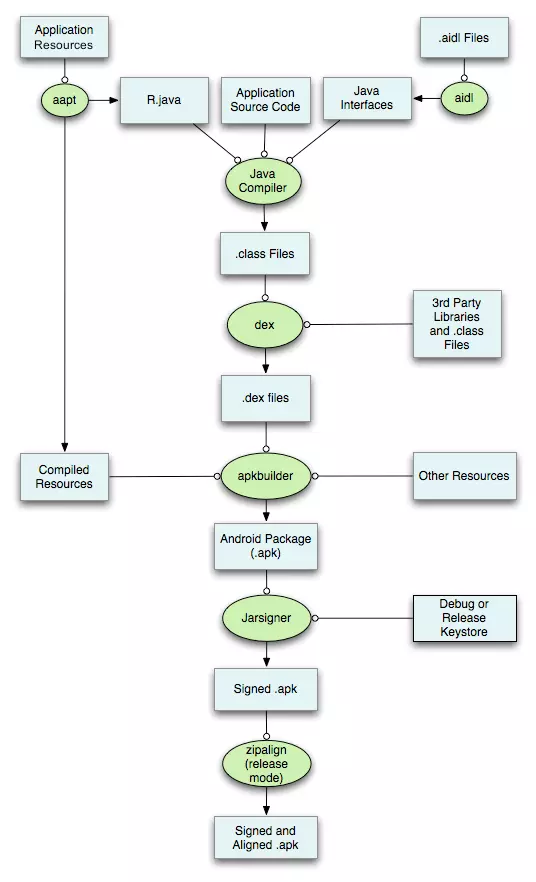
1.打包资源文件,生成R.java文件
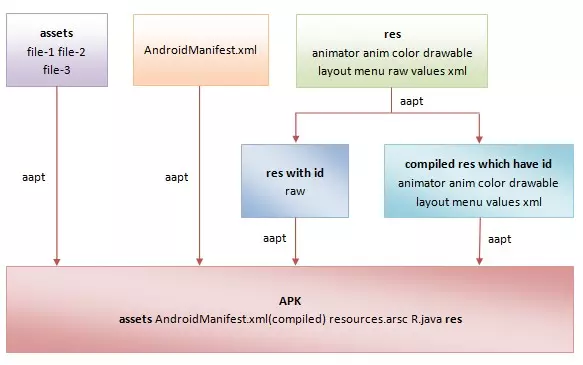
这一过程主要是aapt对res和asset文件夹,AndroidManifest.xml,android库(aar,jar)等的资源文件进行处理。先检查AndroidManifest.xml的合法性,然后编译res与asserts目录下的资源并生成resource.arsc文件,再生成R文件。除了assets和res/raw资源被原封不动地打包进APK之外,其它的资源都会被编译或者处理,大部分文本格式的XML资源文件会被编译成二进制格式的XML资源文件。除了assets资源之外,其他的资源都会在R文件中被赋予一个资源ID。也就是说,R文件中只会存在id,真正的资源存在于resource.arsc中,resource.arsc相当于一个资源索引表,资源id是key,value是资源路径。我们使用drawable-xdpi或者drawable-xxdpi这些不同分辨率的图片的时候,就是依靠resource.arsc根据设备的分辨率选择不同的图片。
2.处理aidl文件,生成相应的.java文件
这一步就是我们代码中的aidl的文件被生成java文件。
3.编译工程源码,生成相应的class文件
R文件,aidl生成的java文件和我们工程中的源代码被javac工具编译成了class文件。
4.转换所有的class文件,生成classes.dex文件
Android系统的dalvik虚拟机的可执行文件为dex格式,程序运行所需的classes.dex文件就是在这一步生成的,使用的工具为dx,dx工具主要的工作是将java字节码转换为dalvik字节码、压缩常量池、消除冗余信息等。
这里在生成dex的时候,就会遇到65536的问题。一个DEX文件中的method个数采用使用原生类型short来索引文件的方法,也就是4个字节共计最多表达65536个method。所以当method数过多的时候,就必须使用multidex。
5.打包生成apk
把所有的dex文件打包为一个apk文件。
6.对apk文件进行签名
apk需要签名才能在手机上安装。平时我们测试主要是使用了一个debug.keystore对apk进行签名。正式发布时需要提供一个符合android开发文档中要求的签名文件。比如jarsigner和APK Signature Scheme v2。
7.对签名后的apk进行对齐处理
一步需要使用的工具为zipalign,它位于android-sdk/tools目录,源码位于android系统资源的build/tools/zipalign目录,它的主要工作是将apk包进行对齐处理,使apk包中的所有资源文件举例文件起始偏移为4字节的整数倍,这样通过内存映射访问apk时的速度会更快。为什么快呢?如果每个资源的开始位置上都是一个资源之后的4n字节,那么访问下一个资源就不用遍历,直接跳到4字节之后即可。
8.混淆proguard:proguard主要的目的是混淆代码,保护应用源代码。次要的功能还有移除无用类等,优化字节码,缩小包体积。
- 压缩(Shrink):检测并移除代码中无用的类、字段、方法和特性(Attribute)
- 优化(Optimize):字节码进行优化,移除无用的指令。
- 混淆(Obfuscate):使用a、b、c、d这样简短而无意义的名称,对垒、字段和方法进行重命名。
- 预检测(Preveirfy):在Java平台对处理后的代码进行预检测,确保加载class文件是可执行的。
2.一些技术点
1.资源去重,极致缩包
前面我们讲到了proguard的功能是混淆代码和缩减体积。但是proguard是不能处理资源文件的。为了解决资源文件的混淆问题,微信推出了AndResGuard。使用AndResGuard可以更加缩减包体积。
除了AndResGuard之外,我们还会遇到资源被重复使用的问题,识别重复资源很简单,只要计算一下md5就行了。并且我们在resources.arsc中可以拿到所有的资源,那么我们就可以对resources.arsc中的所有资源进行处理,根据md5进行去重,把使用了相同资源的资源id都指向同一个资源,把多余的资源删除掉,再回写入resources.arsc就好了。当然,这里面还是有挺多学问的。
2.Transform
Transform是Android gradle plugin提供给开发者的一套API,允许开发者在编译之后,dex之前对class进行修改。开发者可以通过AppExtension或者LibraryExtension进行注册Transform。多个transform会形成一条链。上一个Transform的输出是下一个Transform的输入,因此,Transform的顺序也很重要。
既然有了这个Transform,就意味着我们有机会去操作java的字节码。网上常见的处理字节码的框架有AspectJ, Javasist, ASM。可以利用这些工具进行字节码插桩。这样可以把一些不能耦合在业务代码中的代码在字节码阶段给merge进去。
3.多渠道打包
Android和iOS不一样的是市场和渠道众多,为了区分和统计不同的渠道包的效果,需要有一种方法来标记他们。大家可能会想到使用productFlavor,但是这样的话要打多少包就需要build多少次,耗时非常长。
现在比较好的方案是在apk进行v2签名的时候在签名块中写入一些信息,这样更快更安全。详情可以参考Android美团多渠道打包Walle集成
3.总结
本小节讲解了打包过程,和利用打包机制可以做的一些技术点。打包过程如果能学的透彻的话,还是能给android开发带来很多的可能性。
参考文章:
罗升阳 Android应用程序资源的编译和打包过程分析




 。
。